Why Your AWS Partner Must Engineer Cloud Decisions - Not Just Billable Discounts
Most AWS resellers optimize discounts, not decisions. Learn how an engineered AWS operating model-Control Tower, pods, patterns, and FinOps-turns cloud from an invoice into an operating system.


When most AWS customers talk about their “cloud partner,” what they really describe is a reseller that shows up a few times a year to talk about discounts and commit levels. The day‑to‑day reality is a growing invoice, a backlog of architectural questions, and a nagging sense that nobody is actually accountable for how the environment evolves.
For the overwhelming majority of the market, this is the default motion: the partner optimizes their margin and your discount, but not your decisions. You keep bleeding money in slow motion, often for years, before anyone realizes the reseller has become counter‑productive to your business.
AccelX was built for customers who want something else: an AWS operating model that is engineered, not improvised.
What Goes Wrong When You Treat AWS as “Just a Cloud Invoice”?
In almost every new engagement, we meet teams who cannot clearly answer three basic questions about their AWS estate: who owns which decisions, what changed in the last 12 months, and why the bill looks the way it does. Their previous partner was technically “there,” but the only visible output was a PDF invoice and an occasional discount conversation.
This pattern is more dangerous than it looks. When your AWS partner does not brief you on new capabilities, does not participate in architectural strategy, and does not own any part of your operating model, the environment drifts. New services launch, pricing models evolve, but your workloads stay frozen in last year’s assumptions while the invoice keeps growing. AWS itself frames cloud not as “infrastructure plus invoice,” but as a cloud operating model that links business vision, people, governance, and technology, and that must be revisited as the platform evolves. aws.amazon+1
If no one around the table is explicitly responsible for cost clarity, reversibility, and Day‑2 operations, you will keep overpaying for architecture that no longer fits your business-and you may never connect that bleed to the “trusted” reseller on the slide. AWS’s Operational Excellence pillar explicitly calls for a defined operating model, clear responsibilities, and continuous improvement loops to avoid exactly this kind of drift. docs.aws.amazon
Before and After: What Changes When You Engineer the Operating Model?
Before
- AWS is treated as “infrastructure plus invoice” and a collection of isolated projects.
- The reseller appears around renewals and discounts, but not in architectural decisions.
- Ownership is opaque, Day‑2 operations are reactive, and costs drift upward without explanation.
After
- AWS is treated as a cloud operating model that links business vision, people, governance, and technology.
- Decisions are routed explicitly by risk, with a clear operating model and Control Tower guiding execution.
- FinOps becomes the financial control plane of cloud operations, turning cost into an explained decision signal instead of a monthly shock.
How Does Early Confidence Change the Entire AWS Adoption Curve?
Across startups, scale‑ups, and enterprises, AWS adoption accelerates when customers gain technical, organizational, and economic confidence early-before decisions harden into long‑term constraints. Early confidence allows teams to commit to AWS intentionally, not accidentally.
Cloud makes many execution choices into two‑way doors: you can experiment, learn, and back out with limited pain. Some early decisions, however, quickly become one‑way doors-data gravity, network and identity models, and how you structure ownership of platforms and applications. Once these are set incorrectly, “optimizing the bill” becomes a cosmetic exercise on top of the wrong foundation. AWS Prescriptive Guidance on cloud operating models stresses that early decisions about governance, responsibilities, and ways of working have long‑term impact on cost, risk, and agility, so they must be treated deliberately and revisited as maturity grows. aws.amazon+1
The core job of a serious AWS partner is to help customers distinguish between two‑way and one‑way doors, preserve reversibility where it matters most, and ensure that every irreversible choice is deliberate, well‑governed, and aligned with how the business actually runs.
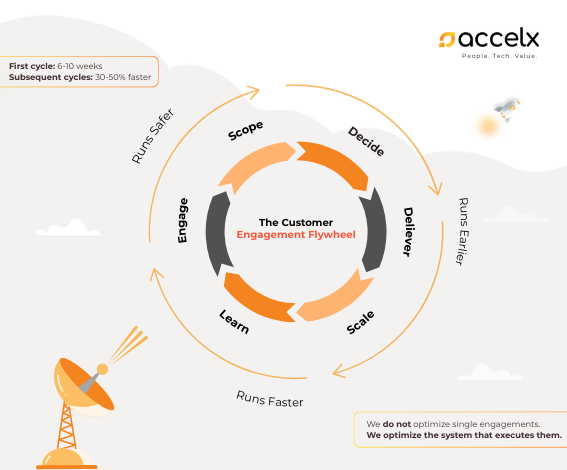
What Is the Early Confidence Flywheel and How Does It Work?
Instead of treating “AWS adoption” as a one‑time project, it should run as a flywheel. Confidence is not a phase you pass through; it is a compounding loop that strengthens with every well‑run engagement.
A healthy flywheel for AWS typically has stages such as Engage, Scope, Decide, Deliver, Scale, Learn. The first 6-10‑week cycle proves that you can run AWS work earlier, faster, and safer-by improving the quality of decisions before heavy investment, not after. Subsequent cycles run significantly faster because more of the system is known, patterns are reused, and failure signals are wired into the way you work.
Over time, this turns AWS from a series of disconnected projects into a single operating system. You are no longer optimizing individual engagements; you are optimizing the system that executes them. AWS guidance similarly recommends treating cloud as an evolving operating model and iterating on processes, ownership, and controls rather than treating migration as a one‑off event. aws.amazon+1
How Does a Control Tower Route AWS Workloads into the Right Execution Lanes?
At the core of this model is a Control Tower-a single, explicit front door for all AWS‑related work. Nothing goes straight to delivery. Every initiative is framed, assessed, and routed based on its decision risk and business context.
You can think in terms of three Execution Lanes to control speed:
A Fast Lane for low‑risk, highly reversible work.
A Standard Lane for medium‑risk initiatives that touch core systems.
A Hold Lane for high‑risk platform decisions that should be isolated and de‑risked before anyone commits deeply.
No delivery happens without routing. The same Control Tower can then be applied to different AWS journeys-a high‑growth SaaS startup under investor pressure, a regional enterprise modernizing a 20‑year‑old core system, or a traditional enterprise tempted by a “big bang” platform decision-by changing routing and guardrails, not by reinventing the system every time.
Case Study: When Your AWS Reseller Becomes Counter‑Productive
We repeatedly meet customers who arrive with the same story: “We have an AWS partner on paper, but we don’t actually know what they do for us. We get a renewal call, a discount slide, and that’s it.” The environment keeps growing in complexity, yet the only visible motion is around the invoice.
In one such case, a mid‑market SaaS company had been on AWS for years with a reseller whose entire engagement model was commercial. No one from the partner ever joined architectural reviews, no one highlighted new AWS capabilities that could simplify their stack, and no one owned cost visibility beyond sending monthly usage reports. The customer’s spend grew steadily, while their architecture stayed frozen in patterns that made sense years earlier.
From the customer’s perspective, this was “normal”-until their workloads were mapped into a structured Control Tower, routing decisions were revisited, and it became clear how many one‑way doors had been walked through without conscious tradeoffs. At that point it was obvious: the reseller was not just neutral; they were actively counter‑effective. By ignoring AWS innovation and refusing to engage at the operating‑model level, they had locked the client into an unnecessarily expensive architecture and a fragile way of working.
This is, in practice, the default experience for the vast majority of companies buying AWS through a generic reseller. They will keep bleeding money and resilience until someone reframes the problem: your issue is not the discount, it is the quality of your decisions.
How Do Pods, Patterns, and Execution Lanes Turn AWS into a Scalable Operating System?
Where most partners sell “more people” or “more hours,” the right model sells a disciplined execution system built around pods and patterns. This is how AWS delivery becomes repeatable instead of heroic.
A pod is a complete, fixed team-for example, a lead architect, cloud and modernization engineers, fractional FinOps and operations, and shared AI/security expertise. Each pod has known capacity, clear unit economics, and full ownership of the work it runs. Pods become the atomic units of your AWS operating system.
Execution happens through patterns, not bespoke one‑offs. Foundational patterns, platform patterns, managed capability patterns, and AI‑enabled patterns are combined to solve recurring classes of problems with known tradeoffs and cost behavior. As pattern reuse grows, execution quality becomes a function of discipline and system design, not individual heroics.
This pod‑and‑pattern model connects directly to the Control Tower and Execution Lanes. As AWS demand grows-sometimes to dozens of leads per month-you route work, scale pods only when execution is ready, and apply “kill switches” when operational signals degrade (for example, pattern reuse drops, margins erode, or delivery slips). Capacity grows when the engine proves it can carry the load, not when demand spikes.
How Does a Clear Team and Ownership Model Remove Ambiguity?
A cloud operating system fails quickly if nobody knows who actually owns what. That is why a team model and ownership model must be explicit, not implied. Every engagement should start by answering a basic question: is the partner there to Empower, Augment, or Provide? The safest default is Empower; anything beyond that must be designed, not drifted into.
Ownership should be defined upfront across platform, operations, applications, and security posture. Responsibilities are designed in advance, not debated during incidents. This is particularly important in AWS environments where multiple vendors, internal teams, and tools overlap-if you cannot draw a clean ownership map, you will spend your next outage arguing over who is supposed to act.
AWS best practices for operational excellence underscore the same principle: clearly defined ownership, escalation paths, and operating procedures are prerequisites for reliable, cost‑effective cloud operations. On the financial side, AWS Cloud Financial Management guidance explicitly calls out cost visibility, allocation, and ownership as foundational capabilities in any mature cloud environment. aws.amazon+2
When FinOps is treated as the financial control plane of cloud operations-not just a reporting layer-cost becomes an explained signal that informs operational priorities instead of a monthly shock. aws.amazon+2
What Business Outcomes Do AWS Customers See When They Optimize the System, Not Just Projects?
Executives rarely ask for “pods and patterns.” They ask for cost control they can trust, change without breaking production, and cloud operations that remain healthy over time. An engineered AWS operating model is built precisely for that reality.
Across engagements, the most effective models commit to four guarantees that do not depend on the specific offer:
- Cost clarity - spend is visible and explainable.
- Risk‑controlled progress - modernization is treated as risk removal, not just new features.
- Predictable execution - delivery is based on repeatable patterns, not heroics.
- Operational continuity - operations remain healthy well beyond the initial project.
AWS Cloud Financial Management and Prescriptive Guidance material describe a similar maturity path: from basic visibility through allocation and budgeting to proactive cost control aligned with business value. When your operating model follows this path, the Before/After becomes clear. Before, leadership sees rising AWS spend, opaque ownership, and reactive firefighting. After, they see decision‑grade cost visibility, clear accountability lines, a predictable cadence of change, and the confidence to use AWS as a strategic platform instead of a necessary utility. aws.amazon+3
What Are the Most Common Mistakes AWS Customers Make with Integrators - and How Can You Avoid Them?
Several mistakes repeat across organizations:
Treating the reseller as a financial instrument instead of a decision partner, and assuming a discount is a strategy.
Allowing architecture, modernization, and operations to evolve without a Control Tower-no routing, no explicit view of decision risk, and no hold lane for dangerous one‑way doors.
Scaling teams before scaling patterns, leading to heroics, low reuse, and margin erosion that eventually kills momentum.
Running MSP or managed operations without a FinOps control plane, leaving cost as “visible but not explainable” and turning every budget conversation into a reactive argument.
AWS and the FinOps community highlight the same failure modes: lack of cost visibility, unclear accountability, and treating cost management as a reporting exercise instead of a continuous control discipline that informs operational decisions. aws.amazon+2
The way to avoid these traps is to start small but deliberately: run a focused entry engagement that targets your highest‑pain area, is time‑boxed to 30-60 days, produces tangible outputs you keep, and creates a clear decision point-without forcing a long‑term commitment. From there, scale only when patterns, pods, and operating signals prove the system is ready.
How Can You Start a Low‑Risk AWS Engagement That Builds Confidence in 6-10 Weeks?
The simplest way to test whether your current AWS partner is helping or hurting you is to run a single, tightly scoped cycle through a different operating model.
In 6-10 weeks, you can:
Engage and scope around your highest‑impact AWS decision bottlenecks.
Decide on routing and governance for those decisions before committing spend.
Deliver a concrete outcome-cost visibility you can take to the board, a safe migration path for a critical system, or a stabilized operating model with clear ownership.
You keep the outputs, and you gain a real signal about what a partner who engineers cloud decisions-not just discounts-can do for your business.If your current experience of “AWS partnership” feels like a discount slide and a growing invoice, the problem is not AWS. The problem is that the system around it was never engineered.
FAQ
- What’s the main problem with “invoice‑only” AWS partners?
They focus on discounts and renewals, but ignore architecture, operating model, and cost governance-so your environment drifts while the bill quietly grows. - What does it mean to “engineer cloud decisions” on AWS?
It means defining how work enters, how risk is assessed, how decisions are routed, and who owns platform, apps, security, and operations-before money is committed. - Why is early confidence more important than a bigger discount?
If early decisions are wrong, discounts just make a bad architecture cheaper for a while; fixing it later is far more expensive than getting the operating model right up front. - How does a Control Tower help AWS customers?
It provides a single entry point and explicit routing (Fast / Standard / Hold lanes), so high‑risk decisions are isolated and low‑risk work can move fast without endangering the core. - What do pods and patterns change in practice?
Pods give you complete, fixed teams with known capacity; patterns give you reusable ways to solve recurring problems-together they replace heroics with predictable execution. - Where does FinOps fit in this model?
FinOps becomes the financial control plane of cloud operations, turning cost and usage into decision signals instead of after‑the‑fact reports. - How can we test this model with low risk?
Run a 6-10‑week entry engagement (for example, cost visibility or migration safety); you keep the outputs and get a real signal without committing to long‑term contracts.



